⚡ Top System Design Algorithms
Production-proven patterns from AWS, Azure, Netflix, Uber, and more
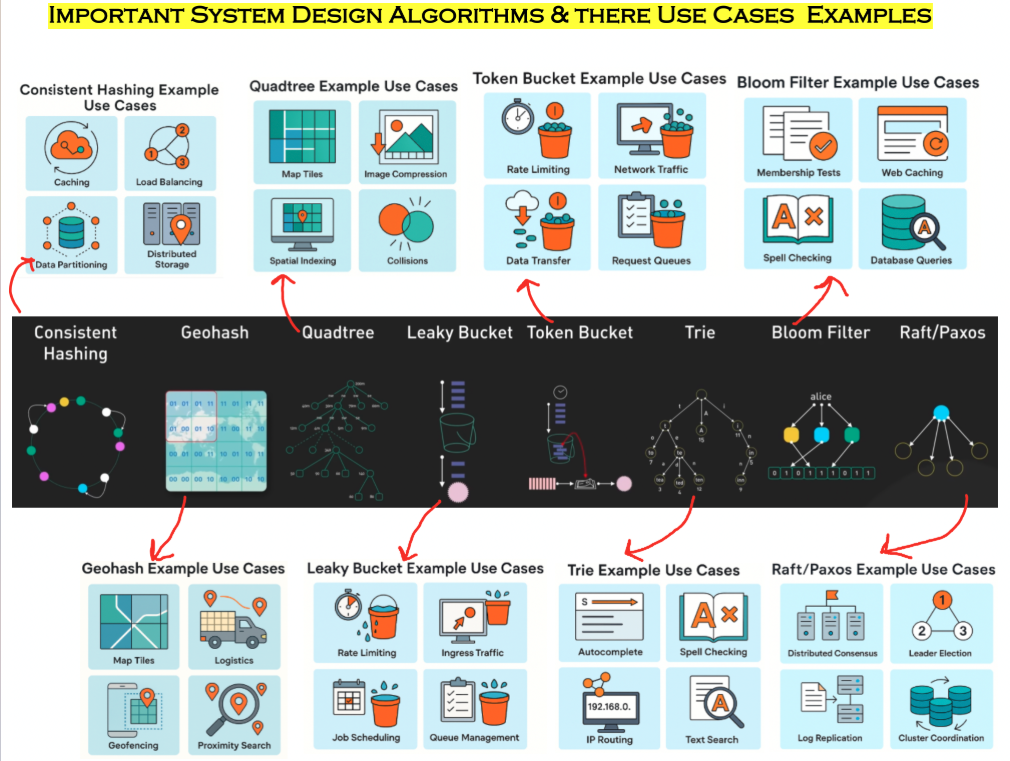
A fast, practical overview of core system‑design algorithms used in production platforms. Each section includes real-world examples from top tech companies and the exact tools they use.
1) Consistent Hashing
Description:
Consistent Hashing maps keys onto a ring such that adding or removing servers requires minimal data movement. It’s designed to keep systems stable during scaling events.
Use Cases:
- Caching — stable key→node mapping reduces cache invalidation.
- Load balancing — even traffic distribution without rebalancing entire clusters.
- Data partitioning — scalable sharding of large datasets.
- Distributed storage — predictable replica assignment with minimal churn. Real-World Examples:
- Amazon DynamoDB — Uses consistent hashing for partitioning data across nodes, enabling seamless scaling.
- Apache Cassandra — Implements consistent hashing for token-based data distribution across cluster nodes.
- Memcached / Redis Cluster — Distributes cache keys across multiple servers using consistent hashing to minimize cache invalidation during node changes.
- Content Delivery Networks (CDNs) — Akamai and CloudFlare use consistent hashing to route requests to edge servers.
- Discord — Uses consistent hashing to distribute millions of voice chat sessions across their fleet of servers.
Tools & Implementations:
- HashiCorp Consul — Service mesh with consistent hashing for load balancing
- NGINX Plus — Supports consistent hashing for upstream server selection
- HAProxy — Load balancer with consistent hashing algorithm support
- Riak — Distributed database built on consistent hashing principles
2) Geohash
Description:
Geohash converts latitude/longitude into a sortable string. Nearby regions share prefixes, enabling fast spatial grouping and neighbor lookups.
Use Cases:
- Map tiles — natural grid structure for rendering zoom levels.
- Logistics — locating nearest delivery hub or truck.
- Geofencing — detection of user entry into predefined areas.
- Proximity search — prefix-based filtering of nearby coordinates.
Real-World Examples:
- Uber / Lyft — Match riders with nearby drivers using geohash-based spatial indexing for sub-second response times.
- Airbnb — Searches for properties near a location by querying geohash prefixes in their Elasticsearch clusters.
- DoorDash — Routes delivery orders to nearby drivers and restaurants using geohash for efficient spatial queries.
- Pokémon GO — Uses geohash for spawning location-based game elements and player proximity detection.
- Tinder — Finds potential matches within a specified radius using geohash-based location filtering.
Tools & Implementations:
- Redis with Geo Commands —
GEOADD,GEORADIUSfor proximity searches - MongoDB Geospatial Indexes — Native support for geohash-based location queries
- Elasticsearch — Geo-point fields with geohash precision for fast spatial searches
- PostgreSQL + PostGIS — Geospatial extension with geohash support
- Firebase Firestore — GeoFire library for real-time location queries
3) Quadtree
Description:
A Quadtree recursively divides 2D space into four quadrants, making it efficient for storing, searching, and querying spatial objects.
Use Cases:
- Map tiling — hierarchical zooming through geographic regions.
- Image compression — subdivide and encode uniform regions efficiently.
- Spatial indexing — fast geo‑queries such as “find objects in area X”.
- Collision detection — prune unnecessary collision checks in games/physics.Real-World Examples:
- Google Maps / OpenStreetMap — Uses quadtrees for efficient map tile rendering at different zoom levels.
- Fortnite / Minecraft — Implements quadtrees (and octrees in 3D) for collision detection and efficient world rendering.
- JPEG 2000 — Image compression algorithm that uses quadtree partitioning for encoding.
- Slack / Discord — Message search indexing uses spatial data structures including quadtrees for efficient range queries.
- Tesla Autopilot — Object detection and tracking systems use quadtree-like structures for spatial partitioning.
Tools & Implementations:
- PostGIS (PostgreSQL) — SP-GiST indexes using quadtree for spatial queries
- Unity Game Engine — Built-in quadtree for 2D physics and collision detection
- D3.js Quadtree — JavaScript library for spatial indexing in visualizations
- OpenCV — Computer vision library with quadtree image segmentation
- Apache SIS — Spatial Information System with quadtree implementations
4) Leaky Bucket
Description:
Leaky Bucket enforces a fixed output rate by processing requests at a constant pace. Useful for smoothing bursts and preventing overload.
Use Cases:
- API throttling — steady processing regardless of request spikes.
- Ingress traffic shaping — protects backend services from overload.
- Job scheduling — releases tasks evenly over time.
- Queue management — predictable throughput for consumers.
Real-World Examples:
- AWS API Gateway — Uses leaky bucket for throttling API requests to protect backend services.
- Azure API Management — Implements leaky bucket rate limiting policies to ensure consistent throughput.
- Twilio — Rate limits SMS and voice API calls using leaky bucket to prevent abuse and ensure fair usage.
- Stripe Payment API — Enforces leaky bucket rate limiting to smooth out payment processing spikes.
- Cloudflare Rate Limiting — Protects web applications from DDoS attacks using leaky bucket algorithm.
Tools & Implementations:
- NGINX rate_limit module —
limit_reqdirective for request rate limiting - Kong API Gateway — Rate limiting plugin with leaky bucket support
- Redis Rate Limiter — Custom Lua scripts implementing leaky bucket
- Envoy Proxy — Rate limit filter with leaky bucket configuration
- Spring Cloud Gateway — RequestRateLimiter filter with Redis-based leaky bucket
5) Token Bucket
Description:
Token Bucket allows controlled bursts: requests consume tokens, and tokens refill at a fixed rate. Great for systems requiring elasticity but bounded rates.
Use Cases:
- API rate limits — temporary bursts followed by throttling.
- Network traffic shaping — enforce bandwidth limits with flexibility.
- Data transfer throttling — smooth uploads/downloads.
- Request queues — gate workloads based on available tokens.
Real-World Examples:
- Twitter API — Rate limits are enforced using token bucket (15-minute windows with burst allowance).
- GitHub API — Allows 5000 requests/hour with token bucket allowing short bursts for better UX.
- Google Cloud APIs — Quota management uses token bucket for per-minute and per-day rate limits.
- Amazon S3 — Throttles request rates using token bucket to ensure consistent performance.
- Netflix API — Internal APIs use token bucket for traffic shaping between microservices.
Tools & Implementations:
- Guava RateLimiter (Java) — Google’s implementation of token bucket for rate limiting
- bucket4j (Java) — Token bucket library with distributed support (Redis, Hazelcast)
- go-rate (Go) — Token bucket implementation for rate limiting in Go applications
- Istio — Service mesh with token bucket rate limiting for microservices
- AWS WAF — Rate-based rules using token bucket for web application protection
6) Trie (Prefix Tree)
Description:
A Trie stores characters as paths in a tree, making prefix-based lookups extremely fast. Common in text processing and routing.
Use Cases:
- Autocomplete — efficient prefix prediction at scale.
- Spell checking — instant dictionary membership lookup.
- IP routing — longest-prefix match for routing tables.
- Text search — quick prefix and keyword queries.
Real-World Examples:
- Google Search — Autocomplete suggestions use trie data structures for instant prefix matching across billions of queries.
- VS Code / IntelliJ IDEA — Code completion engines use tries for fast symbol lookup and autocomplete.
- DNS Resolution — Domain name lookups use trie-like structures for hierarchical name resolution.
- IP Routing (BGP) — Network routers use tries for longest-prefix matching in routing tables with millions of entries.
- Grammarly — Spell checking and word suggestion uses tries for fast dictionary lookups.
Tools & Implementations:
- Elasticsearch Completion Suggester — Trie-based autocomplete for search-as-you-type
- Redis AUTO-COMPLETE — Using sorted sets or trie-like structures for suggestions
- Apache Lucene — Full-text search with trie-based term dictionaries
- Linux Kernel Radix Tree — Page cache and routing tables use compressed tries
- Aho-Corasick Algorithm — Multiple pattern matching using trie structure
7) Bloom Filter
Description:
A Bloom Filter is a probabilistic data structure that quickly tests membership with small memory cost. It may return false positives but never false negatives.
Use Cases:
- Membership tests — identifies “might exist” efficiently.
- Web caching — skip backend lookups for non-existing keys.
- Spell checking — fast, lightweight word existence checks.
- Database queries — avoid expensive reads for missing records.Real-World Examples:
- Chrome Browser — Uses bloom filters to check URLs against safe browsing lists without downloading entire database.
- Bitcoin / Ethereum — SPV (Simplified Payment Verification) clients use bloom filters to query relevant transactions.
- Apache Cassandra — Uses bloom filters to quickly check if an SSTable contains a row before disk I/O.
- Apache HBase — Reduces disk reads by checking bloom filters before scanning HFiles.
- Medium — Avoids showing users articles they’ve already read using bloom filters.
- Akamai CDN — Checks if content exists in cache using bloom filters before querying origin servers.
Tools & Implementations:
- Redis with RedisBloom — Probabilistic data structures including bloom filters
- Guava BloomFilter (Java) — Google’s implementation for membership tests
- Python bloomfilter — PyPI package for memory-efficient membership testing
- RocksDB — LSM-tree storage engine with bloom filter support
- Apache Spark — Uses bloom filters for join optimizations in big data processing
8) Raft / Paxos
Description:
Raft and Paxos are consensus algorithms ensuring distributed nodes agree on consistent state. They enable fault-tolerant coordination within clusters.
Use Cases:
- Distributed consensus — maintain a reliable state across nodes.
- Leader election — select a primary node safely and consistently.
- Log replication — guarantee ordered updates across replicas.
- Cluster coordination — core protocols for systems like etcd and Consul.
Real-World Examples:
- Kubernetes — etcd uses Raft consensus for storing cluster state and configuration data.
- MongoDB Replica Sets — Uses Raft-like protocol for leader election and data replication across nodes.
- Google Chubby / Spanner — Google’s distributed lock service uses Paxos for global consistency.
- Apache Kafka — KRaft mode (replacing ZooKeeper) uses Raft for metadata consensus.
- CockroachDB — Distributed SQL database uses Raft for consistent replication across regions.
- HashiCorp Consul — Service discovery and configuration use Raft for leader election and data consistency.
Tools & Implementations:
- etcd — Distributed key-value store implementing Raft consensus
- Consul — Service mesh and configuration tool with Raft consensus
- Apache ZooKeeper — Coordination service using ZAB (similar to Paxos)
- Atomix — Java framework implementing Raft for distributed coordination
- TiKV — Distributed key-value database using Raft for replication
- Hashicorp Vault — Secrets management with Raft storage backend